On Tuesday I attended the AsyncAPI SIG to discuss a proposal for an AsyncAPI Workshop. During that session Dale Lane announced that he would be holding a session on AsyncAPI and Kafka at the Kafka Summit. This is a live blog post from the session and may contain a few errors/omissions as I try to keep up with the content.
Why do we need AsyncAPI?
Consider a user story where there is a requirement to calculate real time information, it’s an urgent problem to solve. Kafka for stream processing seems like a good fit for the type of problem using Kafka, with a subscription to a Kafka topic. There are quite a few connectors available that work with the problem available externally.
In discussion with a colleague the user finds that there is already a connector available internally. The developer chucks out the old work and starts with the internal project, but the documentation is lacking and hard to understand. If only there was a way to
Discovery of topics and understanding data available is a challenge we face with all types of API and Async is no different.
Getting a feel for what’s in the AsyncAPI Specification
Reviewing a sample AsyncAPI specification available here.
The major parts of the AsyncAPI specification are:
version- Determines this is an AsyncAPI specification and contains the versionid- Unique identifier for a specificationinfo- What is this application for and what’s the spec really about. This is where to give background to a developer picking up the spectags- Help with grouping and organizing multiple specsexternalDocs- There is never enough documentationservers- Terminology is not always an exact match with kafka. e.g.servermeans kafkabrokerin this context.- protocol helps to model multiple different protocols on the specification
channels- models topics for kafkaconsumer/producerare known as subscribe and publish in kafkabindings- used for specific protocol values for how the kafka client should be configuredmessages- describe the exchanges and the format of those exchanges- messages are broken down in
header,payloads,bindingsandexamples - you can define references in the components section to supply reuse across the specifications or perhaps multiple specifications
- messages are broken down in
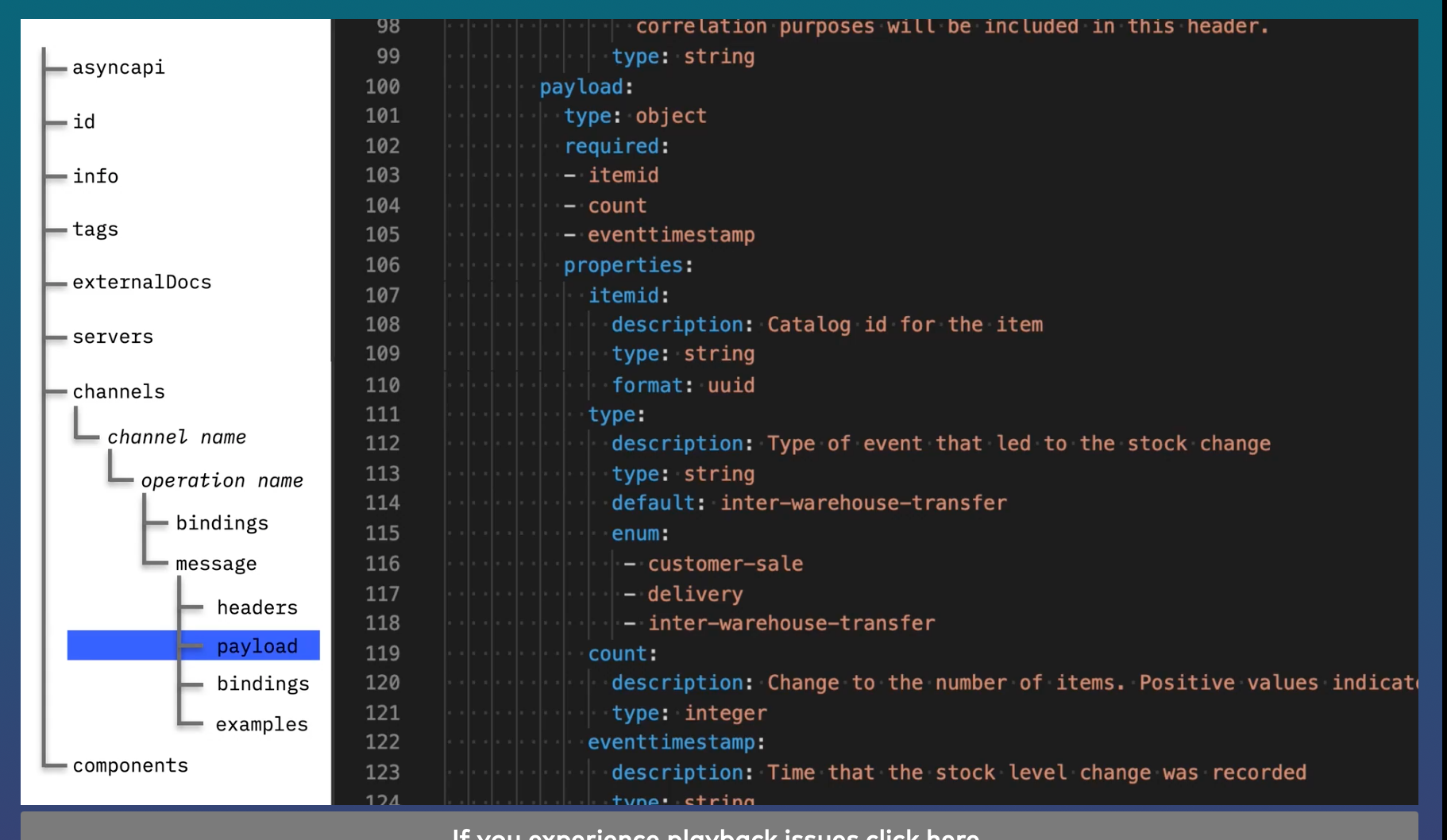
References become an important concept in data modelling and data governance, especially if you want to get consistency across APIs.
If you are using Avro you can still get all of the benefits for describing messages.
In the payloads section in messages you can describe the schemaFormat and contentType and you can link externally to an Avro schema.
AsyncAPI helps to enhance what Avro is doing by providing all of the necessary details about the connection and services in addition to the message specification.
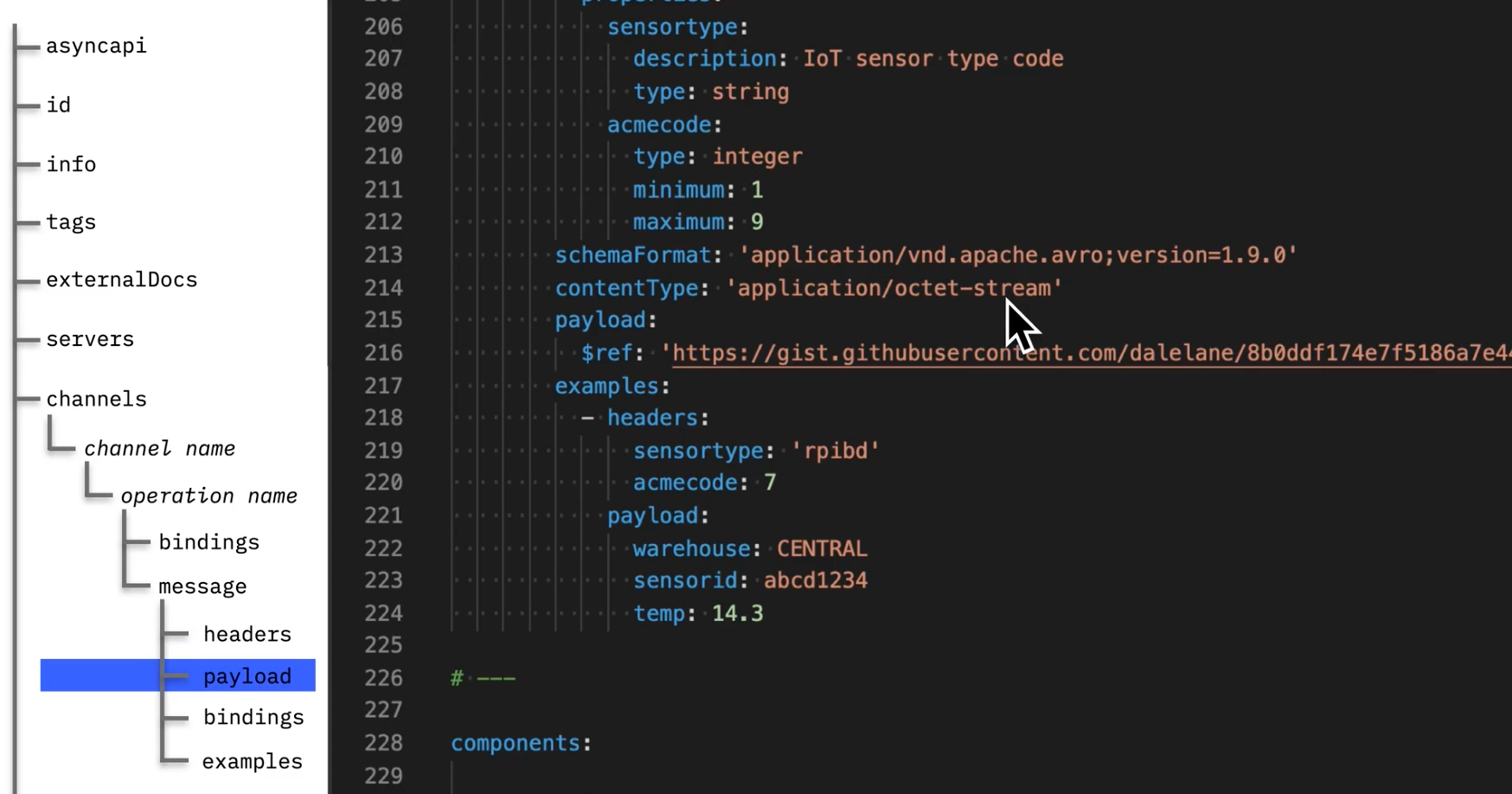
The key takeaways are that the AsyncAPI schema is quite adaptive and provides a specification of AsyncAPIs and complements streaming technologies available.
Demos
Now we have a specification what can we practically do?
Generating Documentation
Async API Preview will generate documentation in VSCode and allow you to build specifications. There is also a web based editor available here, which will resolve external documents.
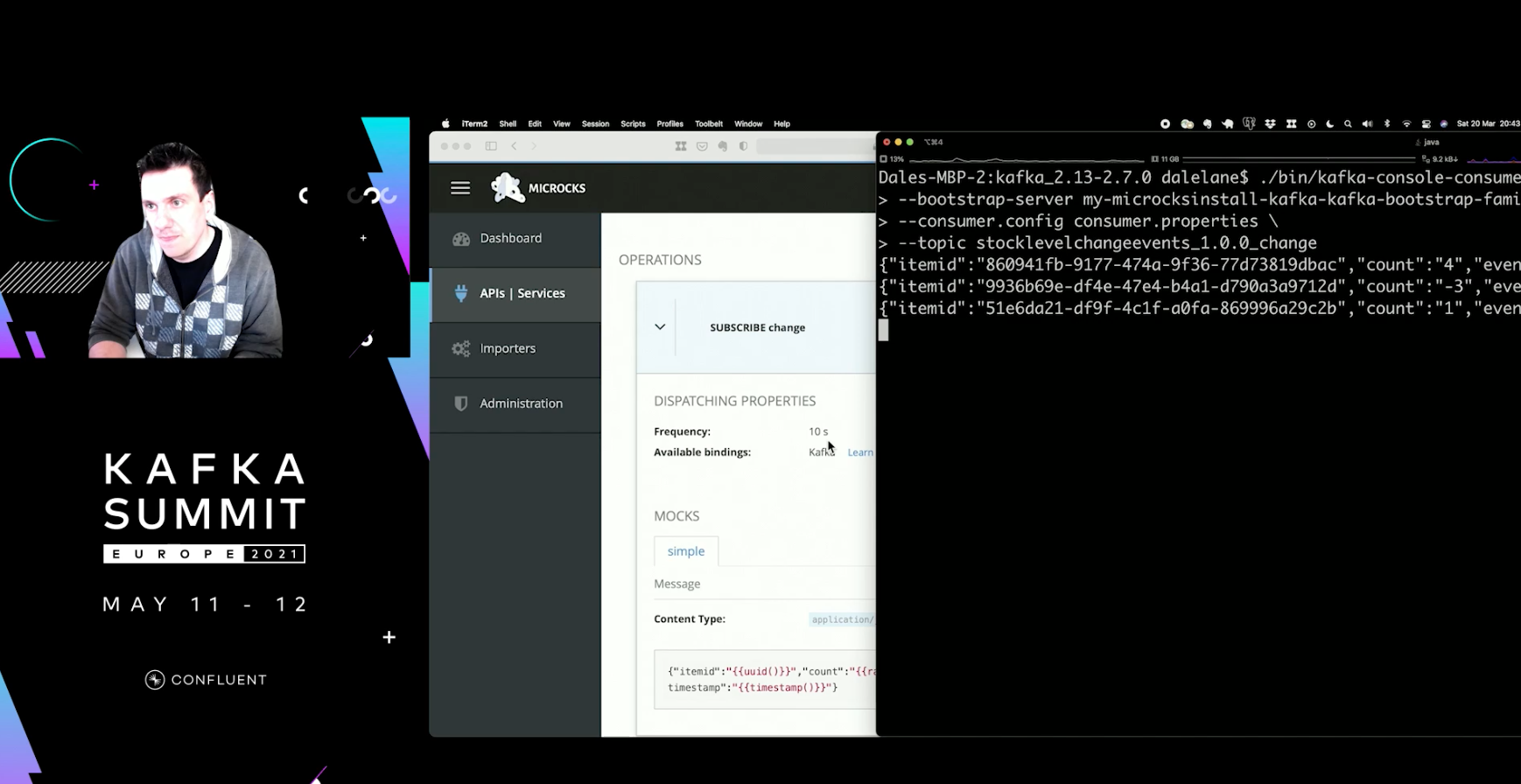
Generating Mock Data
Microcks is an open source tool for mocking and supports AsyncAPI for generating mocks and events on the topic.
Node-RED
Node-RED is a tool for rapid prototyping, you can manually set about the connections and channels. This works nicely with AsyncAPI specification and will automatically populate information in the debug tab.
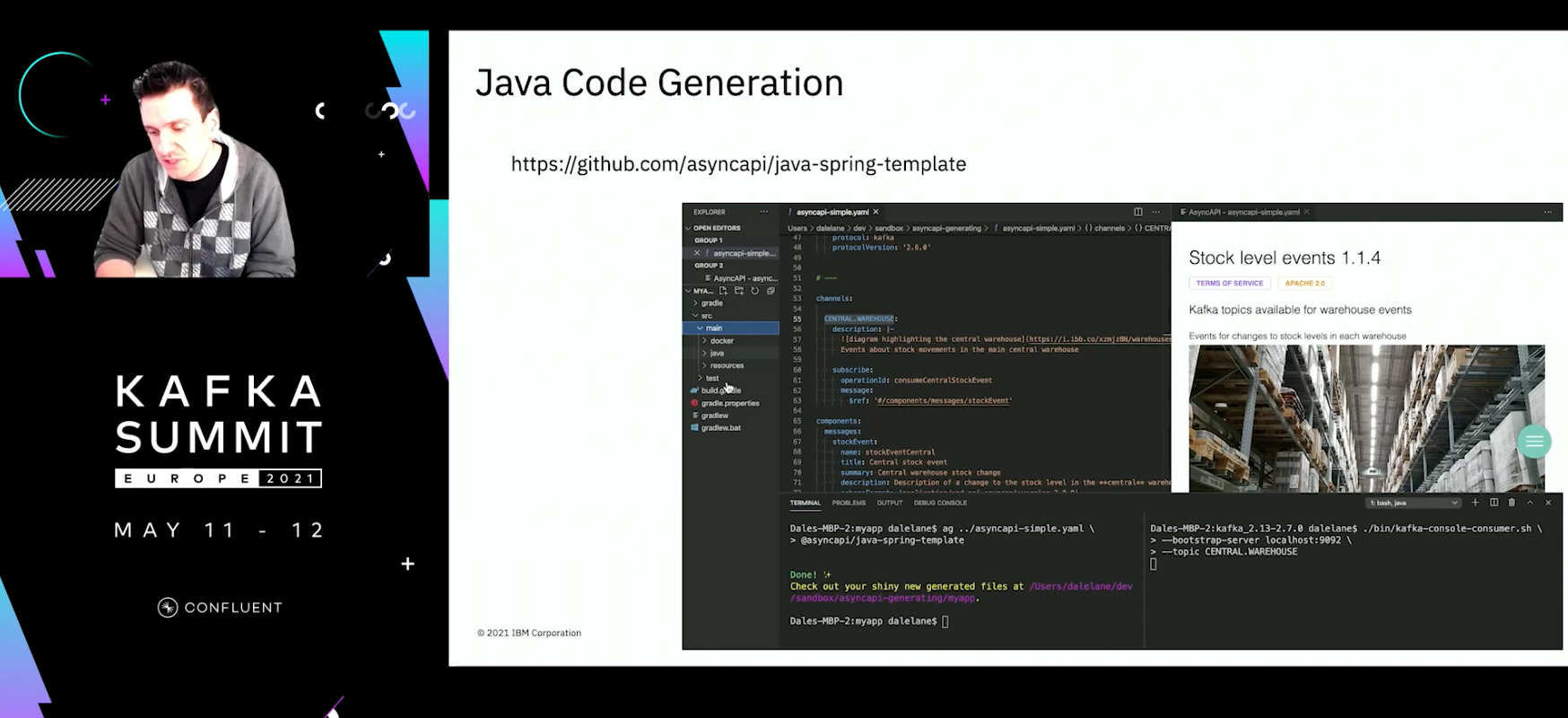
Starting with Code
Sometimes we want to start with code, we can generate code using the ag tool.
This isn’t like Microcks and won’t generate data, but you can go from just the spec to working compiling code in seconds.
There is a similar community recording of the talk available here.